在md文档中添加图片
方法一:
叹号! + 方括号[图片描述 ] + 括号(图片URL )1

方法二:
使用HTML语法规则1
img src="url"
这是一个简易的搜索引擎。该设计是针对PDF文档的搜索。用户提供关键词,搜索引擎返回搜索结果到用户界面,用户通过返回的超链接可查看文档的详细内容。
首先,通过BuildIndex创建文档的索引。然后,将关键词作为Search的参数,返回查询结构,文档内容高亮显示。

创建索引的过程就是将每个文档转化成Document对象,然后调用IndexWriter的addDocument方法将Document对象添加到索引中。
1 | public static void run(String sdir, String indexPath) throws Exception{ |
使用PDF-Box所提供的库从PDF文档中提取内容。
PDFbox是一个开源的、基于Java的、支持PDF文档生成的工具库,它可以用于创建新的PDF文档,修改现有的PDF文档,还可以从PDF文档中提取所需的内容。
1 | public static String readPdf(String path) throws Exception { |
建立好索引后,就可以利用索引进行关键词查询。创建分析器Analyze,采用QueryParser实现模糊查询。
1 | public static ArrayList<String> run(String indexPath, String queryVal) throws Exception { |
高亮显示技术,是搜索引擎常用到的一项重要技术。在搜索引擎开发中引入高亮显示技术,使搜索结果一目了然。
在Lucene5.X的Highlighter包中提供了一个简单的Highlighter功能,PostingsHighlighter。实现步骤为,创建PostingsHighlighter对象,创建对象查询结果,获取查询结果,获取该查询结果所对应的高亮snippets。
1 | public static String[] run(String indexPath, String queryVal) throws Exception{ |
用户界面采用B/S架构(浏览器/服务器模式)实现。服务器端使用Java Servlet技术完成,用户通过浏览器输入待查询关键词,服务器端返回搜索到的相关文档,客户端显示响应的查询结果的路径超链接,以及发现关键词的部分段落。点击超链接查看文档的详细内容。
Index.jsp提供了一个查询初始界面,它接受用户所要查询的的关键词,并将这个词传给Result Servlet做下一步处理。

1 | <body> |
Result Servlet 使用request.getParameter(“q”);获取用户查询的关键词,将关键词作为参数送给Highlighter和Search并获取返回的相应结果集。使用一个循环将获取的信息返回给用户。

1 | protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { |
Document Servlet通过request.getParameter(“path”)获取Result Servlet提供的文档路径。创建Document对象,采用PDFTextStripper读取文档内容,PDDocumentInformation获取文档信息,如标题。按顺序输出文档内容。

1 | protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { |
接口包含接口声明和接口体
接口使用关键字 interface 来声明接口。格式如下:
1 | interfance 接口名字 |
接口体中包含常量的声明(没有变量)和抽象方法两部分。接口体中只有抽象方法没有普通方法,而且接口体中所有的常量的访问权限一定都是 public ,而且是 static 常量(允许省略 public 、 final 和 static 修饰符),所有的抽象方法的访问权限一定都是 public (允许省略 public abstract 修饰符)
1 | interface Font{ |
在Java中,接口由类来实现以便使用接口中的方法。一个类需要在类声明中使用关键字 implements 声明该类实现一个或多个接口。实现多个接口用逗号隔开接口名。
1 | interface Advertisement{ |
运行结果
1 | coompanyA Advertisement |
回溯法是应既带有系统性有带有跳跃性的搜索算法。它在包含问题的所有解的空间树中,按照深度优先的策略,从根节点出发搜索解空间树。算法搜索至解空间树的任一结点时,总是先判断该结点是否肯定不包含问题的解。如果肯定不包含,则跳过对以该结点为根的子树的系统搜索,逐层向其祖先结点回溯;否则,进入该子树,继续按深度优先的策略进行搜索。回溯法在用来求问题的所有解时要回溯到根,且根结点的所有子树都已被搜索遍才结束;而用来求问题的任一解时。只要搜索到问题的一个解就可以结束。这种以深度优先的方式系统地搜索问题的解的方法称为回溯法。
在应用回溯法解决问题时,首先应明确定义问题的解空间。问题的解空间应至少包含问题的一个(最优)解。在确定了解空间的组织结构后,回溯法从开始结点(根结点)出发,以深度优先的方式搜索整个解空间。这个开始结点就成为一个活结点,同时也成为当前的扩展结点。在当前的扩展结点处,搜索向纵深方向移至一个新结点。这个新结点就成为一个新的活结点,并成为当前的扩展结点。如果在当前 扩展结点处不能再向纵深方向移动,则当前的扩展结点就成为死结点。此时,应回溯(往回移动)至最近的一个活结点处,并使这个活结点成为当前的扩展结点。回溯法即以这种工作方式递归地在解空间中搜索,直到找到所要求的解或解空间中已无活结点为止。
n皇后问题来源于国际象棋的一个问题。n皇后问题要求在一个n × n 格的棋盘上放置n个皇后,使得他们彼此不受攻击。按照国际象棋的规则,一个皇后可以攻击与之处在同一行或同一列或同一斜线上的任何棋子。因此,n皇后问题等价于在一个n × n 格的棋盘上放置n个皇后,使得任意两个皇后不能被放在同一行或同一列或同一斜线上。
求解过程从空棋盘开始,设在第1行至第m行都正确的放置了m个皇后,再在第m+1行上找合适的位置放置第m+1个皇后,直到在第n行也找到合适的位置放置第n个皇后,就找到了一个解。接着改变第n行上皇后的位置,希望获得下一个解。另外,在任一行上有n种可能的位置。开始时位置在第1列,以后改变时,顺次选择第2列、第3列…、第n列。当n列也不是一个合理的位置时,就要回溯,去改变前一行的位置。
1 |
|
| 数据域 | 指针域 |
|---|---|
其中,数据域用于存放存储数据元素的值,指针域存储当前元素的直接前驱或者直接后继的位置信息,指针域中的信息称为指针(或链)。
设线性表中的元素是整形,则单链表节点类型的定义为:
1 | typedef struct Node |
p所指结点后插入新元素结点s(s所指结点已生成),基本步骤如下:1 | s->next=p->next; |
即先将p所指结点的后继结点指针赋给s所指的结点的指针域,然后将p所指的结点的指针域修改为s所指的结点
p结点所指结点的后继结点,基本步骤如下:1 | s=p->next; |
先令临时指针s指向待删除的结点,然后修改p所指结点的指针域为指向p所指结点的后继的后继结点,从而将待删除结点从链表中删除,最后释放s所指的结点的空间
1 |
|
正则表达式通过按一定的语法规则在一段文字中进行匹配,然后返回匹配结果。
匹配类型:
在一段文本中发现石否包含某个子串
抽取出符合正则表达式语法的子串
对符合正则表达式的子串进行替换
返回一个布尔值,判断是否匹配
在 Java 中使用正则表达式的方法如下:
Java 中关于正则表达式有两个类,一个接口和一个异常1
2
3
4Java.util.regex.Pattern;
Java.util.regex.Matcher;
Java.util.regex.MatchResult;
Java.util.regex.PatternSyntaxException;
一个 Pattern 对象是一个编译的正则表达式,可以用于任何字符串。 一个 Matcher 对象
是一个单个的用于一个特别目标字符串的实例。 MatchResult 封装了一次成功匹配的数
据。
Pattern.compile()方法将一个字符串编译成正则表达式。 即得到一个 Pattern 对象。
1 | String regex="(<String?>.+?</String?>)"; |
上例中,字符串 regex 是我们写好的正则表达式的字符串。 变量 str 是待匹配的字符串。Pattern p = Pattern.compile(regex);
将正则表达式字符串编译,得到一个 Pattern 对象。
Pattern 对象下的 matcher()方法是使用当前编译的正则表达式去匹配字符串,然后得到一个 Matcher 对象。 Matcher 对象的 find()方法判断是否匹配成功。 正则表达式的一次匹配结果可以包含多个子串,用 Matcher 对象的 group 方法来获得匹配结果的多个子串。 其参数是一次匹配中第几个匹配的子串。如上图是一次匹配中的第一个匹配的子串。 (注:一个正则表达式可以从匹配的字符串中抽取多个子串,其中子串用括号来表示,如上例中有一对括号,因此就有一个匹配的子串。 )
一些 meta characters:
(1)^ 开始字符。例如,^cat 表示匹配一段文字。 这一段文字如果以‘cat’开始,则可以匹配
(2)$ 结束字符。例如,cat$,表示匹配以 cat 结尾的一段文字
(3)[ ] 字符类,列举想要匹配的字符。例如,gr[ea]y,表示匹配含有 grey 或gray 子串的文字
(4)- 在字符类内部使用- 表示范围。例如,[0123456789abcdEFGH]可以写成[0-9a-dE-H]。 注:“-”仅仅在字符类内部是 meta character。
(5)在字符类内部使用^表示非。[^1-6]表示匹配一个字符不是 1 到 6 的。
(6). 匹配任意字符。但在字符类[.]内的“.”就是它的字面意思而不是特殊字符。例如正则表达式 03[.]16[.]76 可以匹配 03.16.76,03\16\76,03.16\76,03\16.76。再看正则表达式 “ [0-9].[0-9]” ,表达的是匹配包含下来子串的字符串“ 数字任意字符数字” 。 即子串的第一个字符是数字,第二个字符是任意字符,第三个字符是数字
(7)| 表示或。例如,Bob|Robert 表示匹配 Bob 或 Robert。正则表达式 Gr[ea]y 可以写成 grey|gray。 也可以写成 gr(e|a)y。但 gr[e|a]y 中的“|”不是特殊字符,是其字面意思。 gr(e|a)y 中括号约束了替换的范围,即两个字符 e 和 a 的替换。
(8)? 表示选择,即在?前面的字符是可选择的。colou?r 即匹配 color 或者 colour。4(th)?表示匹配 4 或者 4th。此处括号对可选择的多个字符做了限制
(9)+ 表示一个或多个立即跟随的字符。例如,[0-9]+表示任意长的数字,012,,91 等
(10)\ 表示后面跟的字符是字面含义,而不是特殊字符。例如,ega.att.com。此处的“.”不是特殊字符而是 literal。 匹配 ega.att.com。
(11){min,max} 定义匹配的范围。例如, [a-z]{1,3}表示字母 a-z 可以出现一次,最多三次。
(12)( ) 有两种含义,一是表示限定范围;二是,当从字符串中取出子串时,括号规定了要提取的子串。
(13)> 特殊字符:
\d 表示数字
\D 表示非数字,等于[^\d]
\w 等同于[a-zA-Z0-9]
\W 等同于 [^\w]
\s 空白符等同于[\f\n\r\t\v]
\S 非空白符
\b 匹配一个 backspace 或 tab 字符
(1)1
2
3
4
5String regex="q[^u]";
String str="Iraq";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
System.out.println(m.find());
结果是false。该正则表达式,要匹配的字符串包含字符q,并且后面必须跟着一个不是u的字符。
(2)1
2
3
4
5String regex="q[^u]";
String str="Qantas";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
System.out.println(m.find());
结果还是false。应为正则表达式对大小写敏感。如果想要消除这种敏感,编译正则表达式时使用1
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
(3)
两个正则表达式
^From|Subject|Date:
^(From|Subject|Date):
匹配结果有什么不同1
2
3
4
5
6
7
8
9String regex="^From|Subject|Date:";
String regex1="^(From|Subject|Date):";
String str="hello Subject: dallas";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
attern p1 = Pattern.compile(regex1, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(str);
Matcher m1 = p1.matcher(str);
System.out.println(m.find());
System.out.println(m1.find());
结果是1
2true
false
这是因为,第一个正则表达式^From|Subject|Date: 表示匹配^From(被匹配的字符串必须以 From 开头)或者Subject (包含子串 Subject) 或者Date:(包含字符串Date:)。第二个正则表达式^(From|Subject|Date):表示匹配的字符串必须以From:或者Subject: 或者Date:开头。
(4)1
2
3
4
5String regex="^h.+d$";
String str="hello world";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(str);
System.out.println(m.find());
结果是true。该正则表达式匹配以h开头,d结尾的字符串。.+表示匹配任意多个字符
(5)1
2
3
4
5String regex="hello\\.world";
String str="Hi, hello.world, Yes";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(str);
System.out.println(m.find())
这段代码中,要匹配一个子串“hello.world”。 因为正则表达式中“.”是特殊字符。因此要匹配该子串,我们写的正则表达式应该是“hello.world”,这里的“\”表示后面的“.”是其字面意思,不是特殊字符。而在 java 中“\”又是特殊字符,我们就再加上一个“\”字符。因此得到了最终的正则表达式”hello\.world”。
(6)我们要提取字符串“ price is 34$, today is April 12” 中描述的价格。1
2
3
4
5
6
7
8
9String regex="([0-9]+)\\$";
String str="price is 34$, today is April 11";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(str);
String s;
if(m.find()){
s=m.group(1);
System.out.println(s);
}
美元符号$在正则表达式中是特殊字符,当前的例子中,文本中包含了美元符号,因此在写正则表达式时,需要在它的前面加上“\”表示其后的美元符号不是特殊字符。另外,括号的作用在于指示这是要提取出的子串。 因此程序运行结果是 34。
(7)匹配字符串“ price is 34$, today is April 12” 中的所有数字,即 34 和 111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16String regex="([0-9]+)";
String str="price is 34$, today is April 11";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m;
String s;
Integer location=0;
while(location<str.length()){
m = p.matcher(str);
if(m.find(location)){
s=m.group(1);
System.out.println(s);
location=m.end();
}else{
break;
}
}
匹配的结果中包含了匹配的子串的起始位置和结束位置,可以用 Matcher 对象的 start()方法和 end()方法来获得。 定义一个 Integer 类型的变量 location,它记录每趟循环中匹配到的子串的结束位置。find(location)方法,表示从当前 location 的位置去寻找匹配的子串。因此在 while 循环中多次去匹配字符串,发现字符串多个与正则表达式匹配的子串。
(8)对于包含小数点的数字的提取1
2
3
4
5
6
7
8
9
10String regex="([0-9]+\\.[0-9]+)";
String str="price is 343.4$, today is April 11";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m;
String s;
m = p.matcher(str);
if(m.find()){
s=m.group(1);
System.out.println(s);
}
字符串中混合了小数和整数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16String regex="([0-9]+(\\.[0-9]+)?)";
String str="price is 343.4$, today is April 11";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m;
String s;
Integer location=0;
while(location<str.length()){
m = p.matcher(str);
if(m.find(location)){
s=m.group(1);
System.out.println(s);
location=m.end();
}else{
break;
}
}
该正则表达式中有两对括号,其中一对嵌入在另一对中。 里面的那一对后面有个?,是用来指示括号里面的内容是“可选择的”。 匹配的子串是外面的那一对括号。
(9)提取出时间1
2
3
4
5
6
7
8
9
10String regex="([0-9]?[0-9]:[0-9][0-9]\\s(am|pm)?)";
String str="It is 9:21 am";
Pattern p = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher m;
String s;
m = p.matcher(str);
if(m.find()){
s=m.group(1);
System.out.println(s);
}
贪婪模式,正则表达式默认的是最大匹配。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16String regex="<[a-zA-Z]+>.+</[a-zA-Z]+>";
String str="<p>hello</p><div>world</div>";
Pattern p = Pattern.compile(regex);
Matcher m;
String s;
Integer location=0;
while(location<str.length()){
m = p.matcher(str);
if(m.find(location)){
s=m.group(0);
System.out.println(s);
location=m.end();
}else{
break;
}
}
结果是1
<p>hello</p><div>world</div>
使用非贪婪模式,正则表达式中的“*”或“+”后加上一个 ?符号,称为惰性符号<[a-zA-Z]+>.+?</[a-zA-Z]+>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16String regex="<[a-zA-Z]+>.+?</[a-zA-Z]+>";
String str="<p>hello</p><div>world</div>";
Pattern p = Pattern.compile(regex);
Matcher m;
String s;
Integer location=0;
while(location<str.length()){
m = p.matcher(str);
if(m.find(location)){
s=m.group(0);
System.out.println(s);
location=m.end();
}else{
break;
}
}
结果是1
2<p>hello</p>
<div>world</div>
不同版本的SAS,使用规则会有所不同
1 | libname data 'D:DATA\'; |
1 | libname data clear; |
最多32个字符长,第一个字符必须是字母或下划线,不能有空格。不能包含特殊字符(如¥,@,#)
不等于: ~=、 <>、ne
等于: eq、=
大于等于:>=、ge
小于等于:<=、le
大于:>、gt
小于:<、lt
逻辑运算符:&、| ~
连接符:||
1 | options user=data; |
一般形式:1
2
3
4DATA 数据集;
语句;
......
RUN;
一般形式1
2
3
4
5proc 过程名 DATA=分析数据集 [选项];
过程语句 / [选项]
过程语句 / [选项]
......
run;
1 | if 条件 then 语句; else 语句; |
1 | 降序排列 |
纵向合并或数据集复制1
2
3data table;
set table1 table2;
run;
横向合并(先对要合并的数据集按相同的变量排序)1
2
3
4data table;
merge table1 table2;
by no;
run;
如果table1与 table2的变量不完全相同,需要在结果中只包含共同的变量:1
2
3
4
5
6
7
8
9data table;
set table1(keep=保留变量名列表)
table2 (keep=保留变量名列表);
run;
或:
data table;
set table1(drop=去除变量名列表)
table2 (drop=去除变量名列表);
run;
如果需要在结果中只包含部分观测:1
2
3
4data table;
set table1(where=(条件))
table2 (where=(条件));
run;
1 | proc sql; |
1 | proc import out = data.table |
1 | proc export data=table |
1 | proc freq data=table; |
SuperScan是由Foundstone公司开发的一款免费的扫描工具,功能强大,扫描速度快。
下面开始介绍软件的使用
这是一款绿色软件,不需要安装,解压后直接运行可执行文件。(需要以管理员身份运)
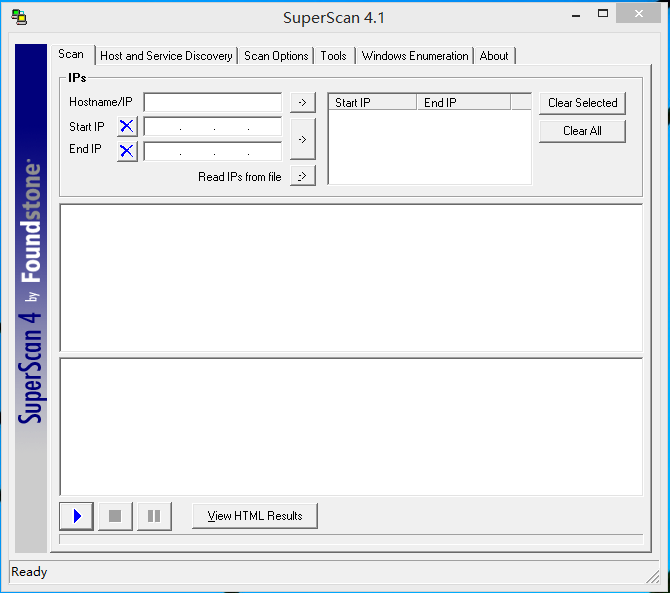
在“start IP” 填入想要扫描的起始IP地址,在“End IP”填入结束扫描的IP地址。单击箭头按钮将目标IP地址范围添加到扫描地址池中,运行端口扫描。扫描结束后,可以点击“查看HTML结果”(View HTNL Results),在浏览器器中查看本次扫描结果。出现TCP端口扫描结果为0,是因为由于主机禁止了扫描器的ICMP扫描响应,因此需要修改对主机的扫描方式。下面是一次扫描结果
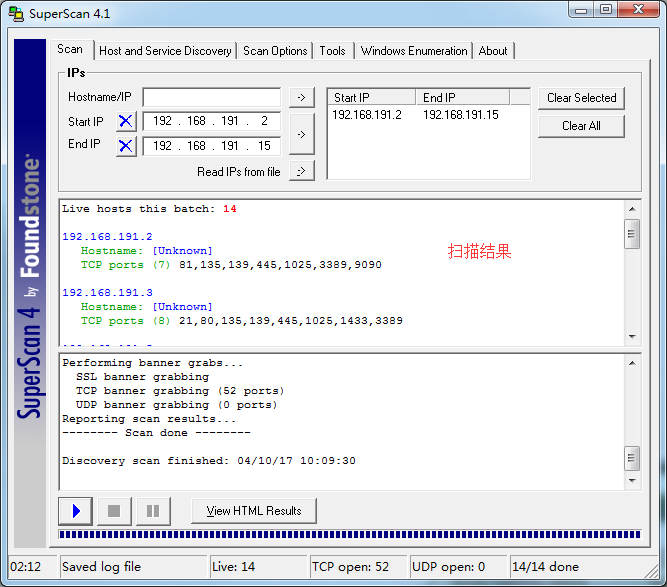
从结果中可以看出该网络中共有14台活动的主机,其中192.168.191.2开放了7个TCP端口:81、135、139、445、1025、3389、9090。主机192168.191.3开放了8个TCP端口:21、80、135、139、445、1025、1433、3389。
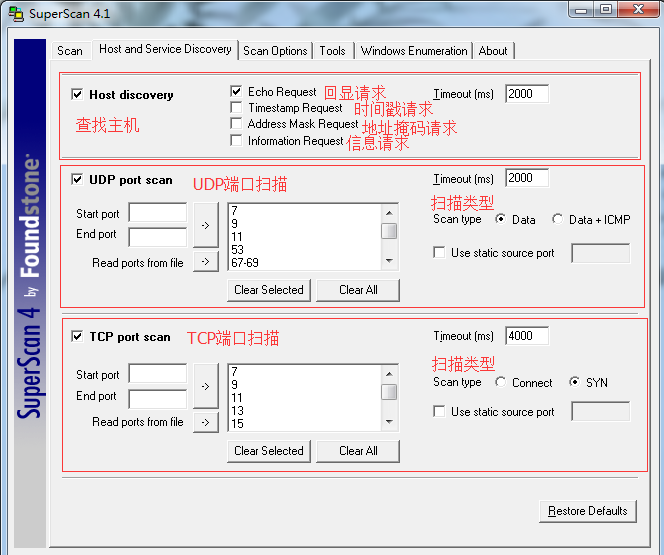
如果扫描结果不满足需求,这就需要对扫描进行一些修改。取消“查找主机”复选框。选中“UDP端口扫描”,将UDP扫描类型设置为Data。选中“TCP端口扫描”,将TCP扫描类型设置为直接连接(Connect)。
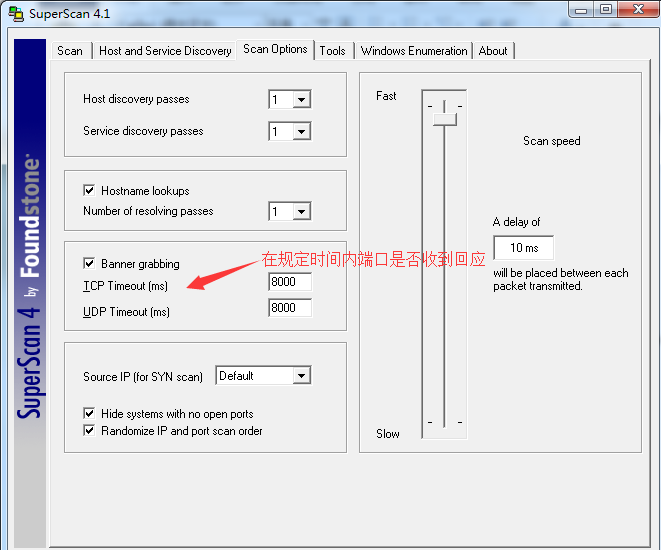
对扫描进程进行进一步的控制。可以设置扫描过程中主机和通过审查的服务数,主机名的解析数,标志获取。标志获取(Banner Grabbing)表示在规定的时间内是否收到回应。
SuperScan的Tools可以较快的得到关于一个主机的信息。正确的输入主机名或IP或默认的连接服务器。选择想要进行的操作,相关信息就会在右边的文本框中显示出来。

根据需要枚举出想要查看的Windows主机的相关信息
安装过程其实并不复杂,执行安装文件后,一直选择 next 就可以了,至于安装路径,根据自己的情况选。下面是步骤图,版本不一样,图可能有些不一样。




安装完成后,检查组件是否安装成功。在命令提示符中输入
1 | node -v |
出现相应的版本信息就表示安装成功。
git的安装过程同样很简单,不需要修改什么地方。下载是安装过程图。











安装完成后,检查组件是否安装成功。在命令提示符中输入
1 | git --version |
出现相应的版本信息表上安装成功。
如果已经有了github账号就不用注册了,直接创建仓库就好。
输入账号,邮箱与密码,点击注册

注册成功后进入这个页面,选择 free, 点击continue

进入这个页面,可以不选,直接 submit

认证邮箱,登录邮箱确认注册信息,确认之后就可以开始创建仓库了
选择 star a project

仓库名与github账号名对应。规则:name.github.io其,他的可以选择性填写 create repository

开启gh-pages功能,点击右上角的 Settings

向下拖动到GitHub Pages,如下图,找到Source 选择分枝并保存,系统会提示name.github.io可以访问了。可以访问后github的配置就结束了。

选择一个地方创建文件夹,存放Hexo。进入Hexo文件夹,右键,选择git bash,输入
1 | npm install -g hexo |
出现WARN可不用理会,继续输入以下命令
1 | npm install hexo --save |
安装完成后,输入命令,验证是否安装成功
1 | hexo -v |
1 | hexo init |
1 | npm install |
1 | hexo -g |
打开浏览器,输入localhost:4000,就可以在本地看到个人博客了

如果浏览器一直没有加载出内容,有可能是端口被占用了,改个端口试试
1 | hexo s -p 5000 |
如果之前已近配置过个人信息就不用配置了
1 | git config --global user.name "GitHub用户名" |
1 | cd ~/.ssh |
提示:No such file or directory 说明你是第一次使用git
1 | ssh-keygen -t rsa -C "邮箱" |
系统会要求你输入密码,可以输入密码,也可以为空。为空提交项目时则不用输密码
在本地设置SSH Key后,需要添加到Github上,已完成SSH连接的设置。
打开本地C:\用户\username.ssh\id_rsa.pub文件(username是你的用户名)。这个文件就是之前生成的SSH Key,默认是隐藏文件夹,需设置显示隐藏文件夹。复制文件内容
登录github网站,点击右上角用户的下三角下的Settings—->SSH Public keys—->add another public keys。
将复制的密钥粘贴到文本框中,点击add key 就可以了。
测试
输入命令
1 | ssh -T git@github.com |
可能会要求输入yes或no,输入yes就好,然后就会出现成功的信息。
在_config.yml文件中,找到Deployment, 然后如下修改
1 | deploy: |
1 | npm install hexo-deployer-git --save |
未安装此插件,在执行 hexo delop时会提示 ERROR Deployer not found: git
到这基本配置应该就结束了,至于主题就选择自己喜欢的去配就好了。如果有什么不对的地方可以指出来,就酱(≧∀≦)ゞ
应该是官方网页吧,基本配置都有 ^_^